Статьи
WikiZero - Автокодіровщік
 Wikipedia
Wikipedia open wikipedia design. 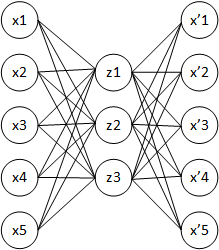
Архітектура автокодіровщіка: при навчанні прагнуть отримати вихідний вектор x 'найбільш близьким до вхідного вектора x
Автокодіровщік ( англ. autoencoder, також - автоассоціатор) [1] - спеціальна архітектура штучних нейронних мереж , Що дозволяє застосовувати навчання без учителя [2] при використанні методу зворотного поширення помилки . Найпростіша архітектура автокодіровщіка - мережа прямого поширення, без зворотного зв'язку, найбільш схожа з перцептроном і містить вхідний шар, проміжний шар і вихідний шар. На відміну від перцептрону, вихідний шар автокодіровщіка повинен містити стільки ж нейронів, скільки і вхідний шар.
Основний принцип роботи і навчання мережі автокодіровщіка - отримати на вихідному шарі відгук, найбільш близький до вхідного. Щоб рішення не виявилося тривіальним, на проміжний шар автокодіровщіка накладають обмеження: проміжний шар повинен бути або меншої розмірності, ніж вхідний і вихідний шари, або штучно обмежується кількість одночасно активних нейронів проміжного шару - розріджена активація. Ці обмеження змушують нейросеть шукати узагальнення і кореляцію в надходять на вхід даних, виконувати їх стиснення. Таким чином, нейросеть автоматично навчається виділяти з вхідних даних загальні ознаки, які кодуються в значеннях ваг штучної нейронної мережі. Так, при навчанні мережі на наборі різних вхідних зображень, нейросеть може самостійно навчитися розпізнавати лінії і смуги під різними кутами.
Найчастіше автокодіровщікі застосовують каскадно для навчання глибоких (багатошарових) мереж . Автокодіровщікі застосовують для попереднього навчання глибокої мережі без вчителя . Для цього шари навчаються один за одним, починаючи з перших. До кожного нового ненавченого шару на час навчання підключається додатковий вихідний шар, що доповнює мережу до архітектури автокодіровщіка, після чого на вхід мережі подається набір даних для навчання. Ваги ненавченого шару і додаткового шару автокодіровщіка навчаються за допомогою методу зворотного поширення помилки. Потім шар автокодіровщіка відключається і створюється новий, відповідний наступного ненавченого шару мережі. На вхід мережі знову подається той же набір даних, навчені перші шари мережі залишаються без змін і працюють в якості вхідних для чергового учня автокодіровщіка шару. Так навчання триває для всіх верств мережі за винятком останніх. Останні шари мережі зазвичай навчаються без використання автокодіровщіка за допомогою того ж методу зворотного поширення помилки і на маркованих даних (навчання з учителем).
Останнім часом автокодіровщікі мало використовуються для описаного «жодного» пошарового предобученія глибоких нейронних мереж. Після того, як цей метод був запропонований в 2006 р Джеффрі Хінтон і Русланом Салахутдінова [3] [4] , Досить швидко виявилося, що нових методів ініціалізації випадковими вагами виявляється досить для подальшого навчання глибоких мереж [5] . Запропонована в 2014 р [6] пакетна нормалізація дозволила навчати ще більш глибокі мережі, запропонований же в наприкінці 2015 р [7] метод залишкового навчання дозволив навчати мережі довільної глибини [5] .
Основними практичними додатками автокодіровщіков залишаються зменшення шуму в даних, а також зменшення розмірності багатовимірних даних для візуалізації. З певними застереженнями щодо розмірності і розрідженості даних, автокодіровщікі можуть дозволяти отримувати проекції багатовимірних даних, які виявляються кращими, ніж ті, що дає метод головних компонент або будь-якої іншої класичний метод [5] .
- ↑ Autoencoder for Words, Liou, C.-Y., Cheng, C.-W., Liou, J.-W., and Liou, D.-R., Neurocomputing, Volume 139, 84-96 (2014 року), DOI : 10.1016 / j.neucom.2013.09.055
- ↑ Навчання багатошарового розрідженого автокодіровщіка на зображеннях великого масштабу, Хуршудов А. А., Вісник комп'ютерних та інформаційних технологій 02.2014 DOI : 10.14489 / vkit.2014.02.pp.027-030
- ↑ GE Hinton, RR Salakhutdinov. Reducing the Dimensionality of Data with Neural Networks (Англ.) // Science. - 2006-07-28. - Vol. 313, iss. 5786. - P. 504-507. - ISSN 1095-9203 0036-8075, 1095-9203 . - DOI : 10.1126 / science.1127647 .
- ↑ Why does unsupervised pre-training help deep learning? .
- ↑ 1 2 3 Building Autoencoders in Keras (неопр.). blog.keras.io. Дата звернення 25 червня 2016.
- ↑ Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift // arXiv: 1502.03167 [cs]. - 2015-02-10.
- ↑ Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition // arXiv: 1512.03385 [cs]. - 2015-12-10.
This page is based on a Wikipedia article written by contributors ( read / edit ).
Text is available under the CC BY-SA 4.0 license; additional terms may apply.
Images, videos and audio are available under their respective licenses.