Статьи
iMath Wiki - Операції реляційної алгебри. Нормальні форми. Зв'язки між відносинами. Проектування баз даних.
- 1НФ
- 2НФ
- 3НФ
- Нормальна форма Бойса-Кодда (НФБК)
- Нормальна форма елементарного ключа (НФЕК)
- Проектування функціональних залежностей
- Алгоритм Бернштейна побудови схеми БД в НФЕК по безлічі ФЗ
- Інфологіческое проектування
- ER-діаграми
- Логічне (Даталогіческое) проектування
- Перехід від ER-діаграм до ФЗ
- діаграми атрибутів
- фізичне проектування
Реляційна теорія так само визначає деякі операції над відносинами. Перелічимо основні операції реляційної алгебри:
вибірка
Повертає відношення, що містить всі записи (кортежі) із заданого відносини, які задовольняють вказаним умовам.
\ (\ Sigma_ {a <10} R \) вибирає з відношення \ (R \) записи, в яких атрибут \ (a \) менше \ (10 \).
проекція
Повертає відношення, що містить всі записи (кортежі) заданого відносини, які залишилися в цьому відношенні після виключення з нього деяких атрибутів.
\ (\ Pi_ {a, b} R \) вибирає атрибути \ (a \), \ (b \) з відносини \ (R \).
перейменування
Повертає відношення, що містить всі записи (кортежі) заданого відносини, при цьому назва одного атрибута замінюється на інше.
\ (\ Rho_ {a / b} R \) повертає всі записи відносини R, в яких атрибут \ (a \) перейменований в \ (b \).
твір, добуток
Повертає відношення, що містить всі можливі записи, які є поєднанням двох записів, що належать відповідно двом заданим співвідношенням.
\ (R \ times S \) повертає відношення, в якому присутні всі атрибути відносин \ (R \) і \ (S \) у всіх можливих комбінаціях.
об'єднання
Повертає відношення, що містить всі кортежі, які належать або одному з двох заданих відносин, або їм обом.
\ (R \ cup S \)
перетин
Повертає відношення, що містить всі кортежі, які належать одночасно двом заданим відносинам.
\ (R \ cap S \)
різниця
Повертає відношення, що містить всі кортежі, які належать до першого з двох заданих відносин і не належать другому.
\ (R - S \)
з'єднання
Повертає відношення, що містить всі можливі кортежі, які являють собою комбінацію атрибутів двох кортежів, що належать двом заданим відносин, за умови, що в цих двох комбінованих кортежі присутні однакові значення в одному або декількох загальних для вихідних відносин атрибутах (причому ці загальні значення в результуючому кортежі з'являються один раз, а не двічі)
\ (R \ bowtie S \)
θ-з'єднання
Повертає відношення, що містить всі можливі кортежі, які являють собою комбінацію атрибутів двох кортежів, що належать двом заданим відносин, за умови θ.
\ (R \ bowtie_ \ theta S = \ sigma_ \ theta (R \ times S) \)
розподіл
Для заданих двох відносин, повертає відношення, що містять атрибути, унікальні для першого відносини і такі записи, для яких декартовій твір проекції першого відносини на унікальні для нього атрибути і другого відносини існують в першому відношенні.
\ (R \ div S = \ pi_ {a_1, a_2, ..., a_n} (R \ cap (\ pi_ {a_1, a_2, ..., a_n} R \ times S)) \)
\ (A_i \ in R, a_i \ notin S \)
Реляційна алгебра має властивість замкнутості, тобто результатом будь-якої операції над ставленням є ставлення. Це дозволяє проводити операції над результатами операцій. Так, зокрема, частим варіантом є вибірка по з'єднанню, або об'єднання проекцій.
Надалі, коли ми будемо розбирати оператори мови SQL, ми спробуємо знайти аналоги цих операцій.
Для спрощення завдань обробки даних, існують так звані нормальні форми реляційної моделі. Вони описують, яким чином повинна бути влаштована структура БД, щоб завдання пошуку легко формалізовивать. Зазвичай виділяють 6 основних нормальних форм, і дві більш строгих версії третього і п'ятого нормальних форм. У практиці проектування СУБД зазвичай обмежуються нормалізацією до третьої або "суворої третьої", оскільки, по-перше, подальша нормалізація не завжди осмислена, по-друге, зусилля, необхідні для подальшої нормалізації, як правило, значно перевищують результат.
Одним з важливих ефектів нормалізації є зменшення кількості можливих аномалій - випадків, коли в БД виникають суперечливі дані.
Для нормалізації використовується операція, яка називається декомпозицією.
1НФ
Ставлення, відповідна реляційної моделі, автоматично знаходиться в 1НФ.
Нагадаємо вимоги реляційної моделі:
- Атрибути мають фіксований тип даних (домен)
- атрибути атомарний
- записи унікальні
- Порядок записів не має значення (немає прихованих атрибутів)
- Порядок атрибутів не має значення (немає прихованих залежностей атрибутів)
2НФ
Для визначення 2НФ, необхідне знання визначення функціональної залежності введене в Лекціі1
Введемо поняття суперключ:
Суперключ це таке безліч атрибутів \ (A \), яке задовольняє вимогу унікальності, тобто не існує записів з повторюваними значеннями \ (A \).
Важливо відзначити, що для відносини з атрибутами \ ((A_1, A_2, \ ldots, A_n) \) існує принаймні один суперключ \ ((A_1, A_2, \ ldots, A_n) \), тобто що включає всі атрибути. Це прямо випливає з вимоги унікальності записів в відношенні.
Мінімальний набір атрибутів, від якого функціонально залежать всі атрибути відносини, будемо називати потенційним ключем.
Більш суворе визначення потенційного ключа:
Потенційний ключ це таке безліч атрибутів \ (A \), яке задовольняє вимогам унікальності і мінімальності, тобто не існує записів з повторюваними значеннями \ (A \) (унікальність) і не існує такого суворого підмножини \ (B \ subsetneq A \), яке б задовольняло вимогу унікальності (мінімальність).
Так само введемо визначення ключових і неключових атрибутів:
Ключові атрибути це атрибути, які входять в який-небудь потенційний ключ неключових атрибут це атрибути, які не входять ні в один потенційний ключ
Відношення знаходиться в 2НФ, якщо
- Воно знаходиться в 1НФ
- Неключових поля функціонально залежать від (будь-якого) потенційного ключа
3НФ
Транзитивная залежність безліч атрибутів \ (C \) транзитивній залежить від безлічі атрибутів \ (A \), якщо існує така безліч атрибутів \ (B \), що \ (A \ rightarrow B \) і \ (B \ rightarrow C \), причому \ (\ require {cancel} B \ cancel {\ rightarrow} A \).
Відношення знаходиться в 3НФ, якщо
- Воно знаходиться у 2НФ
- Відсутні транзитивні залежності неключових атрибутів від потенційного ключа. Інакше, відсутні функціональні залежності неключових атрибутів від неключових атрибутів.
Визначення Кента: кожен неключових атрибут "повинен надавати інформацію про ключі, повному ключі і ні про що, крім ключа".
Визначення Заніоло:
Відношення знаходиться в 3НФ тоді і тільки тоді, коли для кожної його функціональної залежності \ (X \ rightarrow A \) виконується хоча б одна з умов:
- \ (A \ subset X \)
- \ (X \) є суперключ
- \ (A \) - ключовий атрибут (тобто входить до складу потенційного ключа)
Нормальна форма Бойса-Кодда (НФБК)
Відношення знаходиться в НФБК (посиленою 3НФ), якщо
- Воно знаходиться в 3НФ
- Відсутні функціональні залежності між підмножинами ключових атрибутів різних потенційних ключів
Формально: Відношення знаходиться в НФБК тоді і тільки тоді, коли детермінантою (лівої частю) будь-якої його функціональної залежності, що входить в (будь-яке) мінімальне покриття ФЗ цього відносини, є потенційний ключ.
Визначення Дейта: "Кожен атрибут повинен надавати інформацію про ключі, повному ключі і ні про що, крім ключа".
Визначення Заніоло:
Відношення знаходиться в 3НФ тоді і тільки тоді, коли для кожної його функціональної залежності \ (X \ rightarrow A \) виконується хоча б одна з умов:
- \ (A \ subset X \)
- \ (X \) є суперключ.
Нормальна форма елементарного ключа (НФЕК)
НФЕК запропонована Карло Заніоно в 1982 році в якості "компромісу" між 3НФ і НФБК.
Елементарна ФЗ Функціональна залежність \ (f \ in G \), \ (f = X \ to A \) називається елементарної, якщо вона нетривіальна і замикання \ (G ^ + \) не містить ФЗ \ (X '\ to A \) такого, що \ (X '\ subset X \). Елементарний ключ суперключ \ (X \) відносини \ (R \) називається елементарним ключем, якщо \ (R \) задовольняє елементарної ФЗ \ (X \ to A \), де \ (A \) - якийсь атрибут \ (R \) .
Відношення знаходиться в НФЕК, якщо
- Воно знаходиться в 3НФ
- Будь-яка його елементарна ФЗ має в лівій частині суперключ або в правій частині знаходиться підмножина будь-якого елементарного ключа.
Інакше, ставлення знаходиться в НФЕК, якщо для будь-якої його ФЗ \ (X \ to A \) виконується хоча б одна з умов:
- \ (A \ subset X \)
- \ (X \) є суперключ.
- A входить до складу елементарного ключа
Як було сказано раніше, отримати вищу нормальну форму можна за допомогою декомпозиції відносин.
Декомпозиція Складання проекцій \ (S \), \ (T \) вихідного відносини \ (R \), таких, що об'єднання заголовків \ (S \) і \ (T \) збігається з заголовком \ (R \).
Однак, не всяка декомпозиція допустима.
Виділяють два типи декомпозиції, використовуваної для нормалізації.
Декомпозиція без втрат Така декомпозиція \ (R \) в \ ((S, T) \), що \ (R = S \ bowtie T \).
Декомпозиція без втрат (lossless-join) дозволяє відновити вихідне відношення за допомогою операції з'єднання.
Як вибрати декомпозиції без втрат з усіх можливих? Відповідь на це питання дає теорема Хіта.
Теорема Хіта Нехай дано відношення \ (R (A, B, C) \). Якщо \ (R \) задовольняє функціональної залежності \ (A \ to B \), то \ (R = \ pi_ {A, B} R \ bowtie \ pi_ {A, C} R \).
Декомпозиція без втрат, однак, може не зберігати функціональні залежності.
Наприклад, нехай дано відношення \ (R (A, B, C) \), яке задовольняє ФЗ \ (F_R = \ {(A, B) \ to C, C \ to A \} \). По теоремі Хіта, \ (C \ to A \ Rightarrow R = S (B, C) \ bowtie T (C, A) \). Тоді ФЗ відносини \ (S \) \ (F_S = \ {B \ to B, C \ to C \} ^ + \), і ФЗ відносини \ (T \) \ (F_T = \ {C \ to A \} ^ + \). Але \ (((A, B) → C) \ notin (F_S \ cup F_T) ^ + \), і в результаті виявляється втрачена.
Завжди існує декомпозиція без втрат до НФБК.
Декомпозиція, яка зберігає залежності Така декомпозиція \ (R \) в \ ((S, T) \), що замикання безлічі ФЗ відносини \ (R \) збігається з замиканням об'єднання ФЗ відносин \ (S \) і \ (T \).
Декомпозиція, яка зберігає залежності (dependency-preserving) зберігає незмінним замикання ФЗ всіх відносин БД.
Завжди існує декомпозиція до НФЕК, яка зберігає залежності. Однак, не завжди можлива декомпозиція, яка зберігає залежності, до НФБК.
Проектування функціональних залежностей
Декомпозиція відносин по суті здійснюється за допомогою операції проекції. При цьому, ми стверджуємо, що функціональні залежності при декомпозиції зберігаються. Виникає питання: яким чином функціональні залежності поводяться при проектуванні відносин?
Припустимо, що є вихідне відношення \ (R \) з безліччю ФЗ \ (F \), і нехай \ (S \) - якась проекція відносини \ (R \): \ [S = \ pi_A R, \] де A - якесь безліч атрибутів.
Тоді, безліч \ (G \) ФЗ, які залишаться в \ (S \), це ФЗ, які:
- Випливають з \ (F \)
- Включають тільки атрибути, що належать \ (A \)
Цілком ймовірно, що безліч всіх ФЗ такого роду надлишково (не мінімальний). Складність алгоритму пошуку ФЗ відносини \ (S \) в гіршому випадку експоненціально залежить від кількості атрибутів в \ (A \).
Для знаходження всіх ФЗ можна застосовувати замикання атрибутів з \ (A \) по \ (F \). Слід зробити два досить очевидних зауваження:
- Замикання порожнього безлічі і безлічі всіх атрибутів не призводять до отримання нетривіальних ФЗ
- Якщо \ (A \ subset X ^ + \), то побудова замикань для надбезліччю \ (X \) не дасть нових нетривіальних ФЗ в силу правила доповнення.
Так само зрозуміло, що для будь-якого замикання \ (X ^ + \), існують ФЗ виду \ (X \ to B \), де \ (B \ subset X ^ + \).
Таким чином, ми можемо почати з побудови замикань для одиничних множин атрибутів, і додати всі наступні з них ФЗ до безлічі ФЗ \ (G \), якщо вони містять тільки атрибути з \ (A \), а потім, при необхідності, побудувати замикання для множин атрибутів більшої розмірності.
приклад:
Нехай відношення \ (R (A, B, C, D) \) має наступні ФЗ:
- \ (A \ to B \)
- \ (B \ to C \)
- \ (C \ to D \)
Нехай тепер ми отримуємо проекцію \ (S = \ pi_ {A, C, D} R \). Знайдемо ФЗ \ (G \) відносини \ (S \).
Для цього, побудуємо замикання для всіх атрибутів відносини \ (S \) по \ (F \). Оскільки \ (B \) не входить в відношення \ (S \), його замикання не дасть нам ФЗ, що входять в \ (G \). \ [{A} ^ + = {A, B, C, D} \] \ [{C} ^ + = {C, D} \] \ [{D} ^ + = {D} \]
Чи можемо помітити, що \ ({A, C, D} \ subset {A} ^ + \), відповідно, розгляд надбезліччю \ ({A} \) не має сенсу. Отже, єдине непоодинокі безліч атрибутів, що вимагає розгляду це \ [{C, D} ^ + = {C, D}. \]
Запишемо безліч нетривіальних ФЗ \ (S \), що виходять з цих замикань: \ [A \ to C \] \ [A \ to D \] \ [C \ to D \]
Тепер знайдемо мінімальне безліч ФЗ. За правилом транзитивності, ФЗ \ (A \ to D \) випливає з двох інших, тому його можна виключити. У підсумку, отримуємо мінімальну безліч ФЗ \ (S \): \ [A \ to C \] \ [C \ to D \]
Алгоритм Бернштейна побудови схеми БД в НФЕК по безлічі ФЗ
Філіп Бернштейн запропонував алгоритм побудови схеми в 3НФ по ФЗ в 1976 р Пізніше, Заніоло показав, що схема, побудована за цим алгоритмом так само знаходиться в НФЕК.
Даний алгоритм будує, по суті, декомпозицію відносини в 1НФ без втрат і зберігає залежності.
Алгоритм може бути описаний таким чином:
Нехай дано безліч \ (F \) нетривіальних ФЗ. тоді:
- Видалити надлишкові атрибути в детерминантах (лівих частинах) кожної ФЗ. Отримати безліч ФЗ \ (G \).
- Побудувати неізбиточное покриття \ (H \) для \ (G \) (мінімізувати \ (G \))
- Розбити \ (H \) на групи таким чином, щоб ліві частини ФЗ в кожній групі мали однакові ліві частини.
- Об'єднати еквівалентні ключі. Для кожних двох груп \ (H_i \) і \ (H_j \), що мають лівими частинами відповідно \ (X_i \) і \ (X_j \), об'єднати їх, якщо в \ (H ^ + \) існують ФЗ \ (X_i \ to X_j \) і \ (X_j \ to X_i \).
- Скласти відносини. Для кожної групи, скласти відношення, що містить атрибути цієї групи. Ключем кожного відносини будуть атрибути детермінанта групи.
Надмірною атрибутом в детермінанті ФЗ \ (g \ in G \), \ (g = X_1, \ ldots, X_p \ to Y \), є атрибут \ (X_i \), якщо \ (G ^ + \) містить ФЗ \ ( X_1, \ ldots, X_ {i-1}, X_ {i + 1}, \ ldots, X_p \ to Y \).
Інакше, для ФЗ \ ((A \ to B) \ in G \), атрибут \ (a \ in A \) є надлишковим, якщо \ (a \ in (A - \ {a \}) ^ + _ G \ ).
Очевидно, що нові відносини, отримані в результаті декомпозиції, якимось чином пов'язані між собою. Цей зв'язок забезпечується зовнішніми ключами.
Зовнішній ключ Набір атрибутів \ (A \) відносини \ (R \) називається зовнішнім ключем, якщо той же набір атрибутів \ (A \), або якесь перейменування \ (\ rho_B A \), є суперключ нікого іншого ставлення \ (S \ ), причому безліч значень \ (A \) за всіма записами \ (R \) в будь-який момент часу є підмножиною значень \ (\ rho_B A \) за всіма записами \ (S \).
Виділяється чотири типи зв'язків:
Один до одного (1: 1)
Кожного запису відносини \ (R \) відповідає одна і тільки одна запис відносини \ (S \), і навпаки.
Нерідко виявляється, що відносини \ (R \) і \ (S \) можна об'єднати без будь-яких втрат. У таких випадках, єдиною причиною зберігати два відносини може бути зв'язок цих відносин з різними сутностями.
Один до багатьох (1: M) Кожного запису відносини \ (R \) відповідає \ (M \ geq 0 \) записів відносини \ (S \), але кожного запису відносини \ (S \) відповідає тільки один запис відносини \ (R \). Багато до одного (M: 1) Кожного запису відносини \ (R \) відповідає тільки один запис відносини \ (S \), але кожного запису відносини \ (S \) відповідає \ (M \ geq 0 \) записів відносини \ (R \) Багато до багатьох (M: N) кожного запису відносини \ (R \) відповідає \ (M \ geq 0 \) записів відносини \ (S \), і кожного запису відносини \ (S \) відповідає \ (N \ geq 0 \) записів відносини \ (R \)
Зв'язки так само діляться на ідентифікують і не ідентифікують.
идентифицирующая зв'язок
це такий зв'язок, яка вимагає існування значення первинного ключа пов'язаного відносини. Іншими словами, запис в пов'язаному щодо необхідна для ідентифікації запису в даному.
Наприклад, дані відносини Directory = (Id, Name) і File = (Id, Name, DirectoryId), пов'язані 1: М через зовнішній ключ File.DirectoryId ⇆ Directory.Id. У даній моделі, файл не може існувати без директорії, і цей зв'язок є ідентифікуючої, оскільки вимагає існування значення Directory.Id, рівного File.DirectoryId.
Чи не ідентифікує зв'язок
зв'язок, що не є ідентифікуючої.
Наприклад, дані два відносини Account = (Id, Type) і AccountType = (Type, Description), пов'язані M: 1 через зовнішній ключ Account.Type ⇆ AccountType.Type. У даній моделі Type може бути не заданий. Таке стосується не буде ідентифікує, оскільки записи в Account і AccountType можуть існувати незалежно один від одного.
Проектування баз даних - це процес концептуалізації та реалізації бази даних, що описують якусь предметну область, для вбудовування в конкретну СУБД.
Зазвичай виділяють наступні етапи проектування БД:
- Концептуальне (інфологічне) проектування.
- Логічне (Даталогіческое) проектування
- фізичне проектування
Розглянемо ці етапи більш детально.
Інфологіческое проектування
Інфологіческое проектування побудова семантичної моделі предметної області, тобто інформаційної моделі найбільш високого рівня абстракції.
Такі моделі, як правило, будуються без орієнтації на конкретну СУБД або навіть модель даних. Сенс побудови інфологічної моделі полягає у виділенні основних сутностей предметної області та їх властивостей (атрибутів).
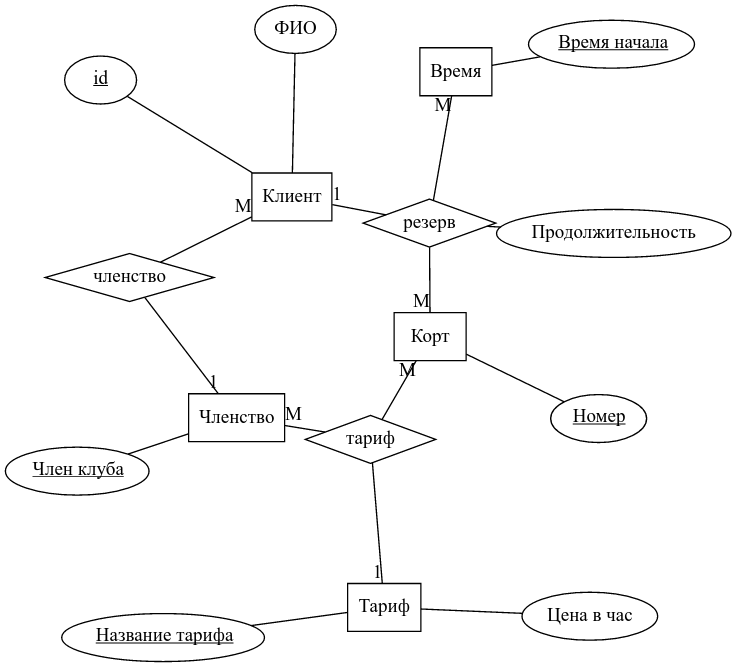
Один з популярних способів побудови інфологічної моделі - побудова ER-діаграм.
ER-діаграми
На відміну від діаграм атрибутів, ER-діаграми, крім безпосередньо атрибутів, включають так само в явному вигляді "сутності" і "зв'язку" між ними, звідки, власне, і походить назва: entity-relationship diagram, або діаграма суті-зв'язку.
І суті, і зв'язку можуть володіти набором атрибутів. Суті без атрибутів - явище досить безглузде, як Кантовська "річ в собі". Зв'язки без атрибутів - явище, навпаки, вельми поширене.
Строго кажучи, на діаграмі позначаються класи сутностей. Щоб уникнути плутанини, під словом "сутність" будемо розуміти набір атрибутів, а набір значень цих атрибутів будемо називати екземпляром сутності.
У найбільш поширеною нотації, атрибути позначаються овалами, сутності - прямокутниками, а зв'язки - ромбами.
Сутності та зв'язку з'єднуються между собою лініямі. Існують різні нотації, що мають на увазі різну ступінь подробиці опису. Ми будемо використовувати спрощену схему, в якій для кожної лінії надписується, якраз сутність бере участь в зв'язку: 1 або багато разів (М). У зв'язку можуть брати участь дві або більше сутностей. Хоча багатозначні зв'язку (зв'язку, в яких беруть участь більше двох сутностей) - не надто поширене явище, іноді вони бувають необхідні.
Для кожної сутності можуть бути виділені один або кілька ідентифікують атрибутів, так само, по аналогії з реляційною моделлю, званих ключем. Значення ключа сутності однозначно ідентифікують екземпляр сутності, так само як значення потенційного ключа відносини однозначно ідентифікує запис. Зрозуміло, що ключів може бути кілька - по крайней мере один ключ, що включає всі атрибути сутності, повинен існувати - назвемо його тривіальним. Крім того, можливо існують ключі-підмножини тривіального. Домовимося, що з усіх ключів ми вибираємо один мінімальний, і використовуємо його (назвемо його первинним).
Атрибути, що входять в первинний ключ на ER-діаграмі підкреслюються.
Розглянемо ER-діаграму для прикладу з тенісними кортами .
Логічне (Даталогіческое) проектування
Логічне проектування створення схеми бази даних на основі конкретної моделі даних, наприклад, реляційної моделі даних. Для реляційної моделі даних даталогіческая модель - набір схем відносин, зазвичай із зазначенням первинних ключів, а також «зв'язків» між відносинами, що представляють собою зовнішні ключі.
На етапі логічного проектування враховується специфіка конкретної моделі даних, але може не враховуватися специфіка конкретної СУБД.
Перехід від ER-діаграм до ФЗ
ER-діаграми цілком природним чином можуть бути перетворені до ФЗ.
Кожна сутність має на увазі ФЗ неключових атрибутів від ключових, оскільки значення ключових атрибутів однозначно визначають значення інших - інакше, значення неключових атрибутів є (взагалі кажучи, дискретна) функція від значень ключових атрибутів.
Зв'язки двох сутностей типу один-до-одного встановлюють взаємно-однозначна відповідність між сутностями, тобто взаємні ФЗ між ключами сутностей. Атрибути самої зв'язку функціонально залежать від всіх ключів входять в зв'язок сутностей.
Зв'язки двох сутностей типу один-ко-многим і багато-до-одного природним чином моделюють функціональну залежність між ключовими атрибутами відповідних сутностей: в лівій частині ФЗ знаходяться ключові атрибути сутності, що входить в зв'язок багаторазово, а в правій - ключові атрибути сутності, що входить в зв'язок одноразово, а так же атрибути самої зв'язку (якщо є). Можна сказати, що ФЗ моделює зв'язок типу багато-до-одного.
Це ж міркування природним чином узагальнюється на багатозначні зв'язку: кожна з однократно входять в зв'язок сутностей (точніше, її ключі) функціонально залежать від усіх багаторазово входять до зв'язок сутностей. Те ж саме можна сказати про атрибути самої зв'язку.
Нарешті, зв'язок типу багато-до-багатьох можна розглядати як окремий випадок багатозначною зв'язку: всі атрибути зв'язку функціонально залежать від усіх ключових атрибутів пов'язаних сутностей.
Таким чином:
- Кожна сутність \ (E \) перетвориться до ФЗ виду \ [K_E \ to A_E, \] де \ (K_E \) - безліч ключових (ідентифікують) атрибутів сутності \ (E \), а \ (A_E \) - безліч всіх атрибутів суті \ (E \).
- Кожна зв'язок \ (R \) між сутностями \ (E_1, \ ldots, E_n \), що входять в зв'язок багаторазово і \ (S_1, \ ldots, S_m \), що входять в зв'язок одноразово, перетворюється до ФЗ виду \ [K_ {E1 } \ cup \ ldots \ cup K_ {En} \ to A_R \ cup K_ {S1} \ cup \ ldots \ cup K_ {Sn}, \] де \ (K_i \) - ключі відповідних сутностей, \ (A_R \) - атрибути зв'язку, і ФЗ виду \ [K_ {Si} \ to K_ {S1} \ cup \ ldots \ cup K_ {Sn} \].
Слід зробити одне важливе зауваження: якщо зв'язок багато-до-багатьох (можливо багатозначна) не має атрибутів, то вона дасть виключно тривіальні функціональні залежності. Це, як правило, небажано, оскільки при формальному аналізі в результаті призведе до втрати зв'язку з цим. Це пов'язано з тим, що зв'язок багато-до-багатьох є нефункціональної залежністю. Рішенням цієї проблеми може бути введення фіктивного атрибута з порожнім доменом, скажімо, \ (\ theta \), унікального для цих питань. Це дозволить формально аналізувати функціональні залежності для - фактично - невизначеною функції.
діаграми атрибутів
Крім безпосереднього запису ФЗ в стовпчик, існує більш наочний спосіб представлення ФЗ відносин. Він так само може використовуватися для нормалізації відносини принаймні до 3НФ.
Діаграми атрибутів будуються таким чином. У овалах записуються всі атрибути даної предметної області, і між ними малюються стрілки, відповідні ФЗ, присутнім в системі. У разі наявності складових лівих частин ФЗ, вводяться проміжні вузли, що позначаються точкою.
Наприклад, побудуємо діаграму атрибутів для нашого прикладу з тенісними кортами .

Використання діаграм атрибутів дозволяє досить просто виявляти транзитивні залежності і виділяти окремі відносини методом простої угруповання пов'язаних вузлів (атрибутів).
Як приклад, виділимо на цій діаграмі відносини. Спочатку виділимо всі можливі ключові атрибути за наступним ознакою: якщо який-небудь атрибут функціонально залежить від даного, то даний атрибут є ключовим.

Тепер для кожного ключового атрибута виділимо його і всі атрибути, безпосередньо залежать від нього, в окрему групу.
Це дозволить нам виділити групи атрибутів, які не мають транзитивних залежностей, в яких все неключових атрибути залежать від потенційного ключа.

Подвійний лінією позначені зовнішні ключі.
Нескладно помітити, що кожна з виділених груп є відношенням в 3НФ.
фізичне проектування
Фізичне проектування створення схеми бази даних для конкретної СУБД. Специфіка конкретної СУБД може включати в себе обмеження на іменування об'єктів бази даних, обмеження на підтримувані типи даних і т.п. Крім того, специфіка конкретної СУБД при фізичному проектуванні включає вибір рішень, пов'язаних з фізичним середовищем зберігання даних (вибір методів управління дисковою пам'яттю, поділ БД по файлах і пристроїв, методів доступу до даних), створення індексів і т.д.
Як вибрати декомпозиції без втрат з усіх можливих?Виникає питання: яким чином функціональні залежності поводяться при проектуванні відносин?